HTML 스크래이핑으로 네이버 환율
사전준비
BeautifulSoup을 불러오기 위해,,,
1
2
!pip install bs4
html문자열은 파이썬에서 다뤄야 한다.
BeautifulSoup을 이용하여 html을 문자열 엘리먼트 객체로 바꿀 수 있다!- type이
BeautifulSoup임.
네이버 환율정보 가져오기
1
2
3
4
5
6
7
8
9
10
11
import requests
from bs4 import BeautifulSoup
url = "https://finance.naver.com/marketindex/"
response = requests.get(url)
page = response.content # content : 접속한 웹 서버의 응답을 문자열로 가져오는 속성
soup = BeautifulSoup(page, 'html.parser') # html.parser : 문서를 컴퓨터가 이해할 수 있는 구조로 변환
soup # 출력 결과 확인 및 어떻게 데이터에 접근할지 확인
필요한 데이터만 가져오기
1
2
exchange_list = soup.select("#exchangeList > li")
exchange_list
하나만 선택하여 스크래이핑 테스트 진행
- 실제로 현업에서 개발할 때, 이렇게 테스트를 먼저 해보고 개발.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 하나만 잡아서 스크래이핑 테스트
test_fin = exchange_list[0]
# 대상 화폐
test_fin.select_one("h3.blind").text
# 환율
float(test_fin.select_one("span.value").text.replace(",",""))
# 변동
float(test_fin.select_one("span.change").text)
# 결과 (하락)
test_fin.select_one("span.blind")[-1].text
# 결과
test_fin.select_one("span.change").nextSibling.nextSbling.text
테스트가 잘 됐으니 예쁘게 코딩하자
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 필요한 데이터를 리스트에 저장
c_name_list = []
exchange_rate_list = []
change_list = []
updown_list = []
for exchange in exchange_list:
c_name = exchange.select_one("h3.h_lst").text
exchange_rate = float(exchange.select_one("span.value").text.replace(",", ""))
change = float(exchange.select_one("span.change").text)
updown = exchange.select("span.blind")[-1].text
print(c_name, exchange_rate, change, updown)
c_name_list.append(c_name)
exchange_rate_list.append(exchange_rate)
change_list.append(change)
updown_list.append(updown)
1
2
3
4
5
6
7
8
9
10
11
12
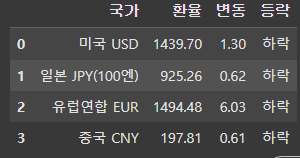
# 모은 리스트로 데이터프레임 만들기
import pandas as pd
exchange_datas = {
"국가": c_name_list,
"환율": exchange_rate_list,
"변동": change_list,
"등락": updown_list
}
df_exchange = pd.DataFrame(exchange_datas)
df_exchange
[결과]
만든 데이터프레임 csv로 저장하기
1
df_exchange.to_csv("파일경로/이름.csv", index=False)
This post is licensed under CC BY 4.0 by the author.