10. 데이터 집계_분포와 통계량
10. 데이터 집계_분포와 통계량
데이터 리소스는 titanic_train.csv를 사용합니다.
10. 데이터 집계_분포와 통계량
집계란?
- 모아서 계산한다.
- 집계의 결과는 무조건 1개
- 각 그룹별 N(N개의 레코드 수)를 집계하면 1개(통계값,대표값)이 나옴.
- 위의 과정을 Reduce(공학적 관점), aggreagtion(통계 관점)
- ex. 평균, 표준편차, 중앙값, 분산, 최빈값 등,,,
분포 및 요약 통계
df.describe()
- 컬럼 별 값의 개수, 평균, 표준편차, 최솟값, 최댓값, 사분위수 보여주기.
- 문자열 데이터는 X.당연함. 통계량을 위한 함수기 때문.
1
df.describe() # 당연히 문자열 데이터는 나오지 않음. 통계량을 위한 것이라.
Tip)
- 데이터를 볼 때 평균값과 중앙값을 비교해본다. (데이터가 쏠렸는지 확인 가능)
- 형제(SibSp)가 많이 탔으면 생존 확률이 높았을까? -> 이런 것을 분석하는 게 EDA
- 표준편차가 많이 난다면 -> 값들의 차이가 크다
대푯값
| 메소드 | 설명 |
|---|---|
| min() | 최솟값 |
| max() | 최댓값 |
| mean() | 평균 |
| median() | 중간값 |
| std() | 표준편차 |
| var() | 분산 |
| quantile() | 분위수 |
숫자 형태(int, float)의 데이터에 대해서만 집계
1
2
3
4
5
# df.min() # type ERROR : 문자열은 연산이 안 되기 때문에.
df.min(numeric_only=True)
df.quantile(0.9, numeric_only = True) # 100개로 정렬 했을 때 90번째에 있는 값?
변수의 상관관계 확인하기 (찍먹)
- 상관관계 분석 : 두 변수의 관련성을 구하는 것
- 두 변수 간의 연관된 “정도”이지, “인과관계”를 설명하진 않는다. (인과관계를 설명하는 것은 확률!!!)
- 상관계수 = 두 변수가 함께 변하는 정도(공분산) / 두 변수가 각각 변하는 정도(각 변수의 분산의 곱- 정규화)
1
df.corr(numeric_only = True) # 숫자 값만 계산한다는 것
1
2
3
4
5
6
7
8
import seaborn as sns
import matplotlib.pyplot as plt
sns.heatmap(
df.corr(numeric_only = True),
annot=True # 표 위에 숫자 쓸까?-?
)
plt.show()
11. 데이터 집계
titanic_train.csv 사용
groupby
- 집계에서의 “집” 부분
- 그룹 후 사용할 수 있는 함수들 (“계”)
- NaN값은 집계에서 제외됨!!
- 그룹 내의 데이터가 n개 였다면, 계산을 수행하면 1개가 된다!!!(Reduction)
| 함수 | 설명 |
|---|---|
| count() | 행의 개수 |
| nunique() | 행의 유니크한 개수 |
| sum() | 합 |
| mean() | 평균 |
| min() | 최솟값 |
| max() | 최댓값 |
| std() | 표준편차 |
| var() | 분산 |
단일 그룹
- 기준이 한 개
1
2
# "집"
df.groupby("Pclass") # 출력 결과 : Pclass 기준 1등급/ 2등급 / 3등급으로 그룹이 나뉘어짐.
1
2
# "계"
df.groupby("Pclass").count() # 그룹별로 모인 데이터에 대한 계산을 수행
1
df.groupby("Pclass").sum(numeric_only = True) # 숫자인 값에 대해서만 sum하겠다.
특정 값에 대해서만 집계하기
1
2
# 특정 컬럼에 대해서만 집계
df.groupby("Pclass")["Age"].sum()
Fancy Indexing으로 여러 컬럼에 대해 집계
1
df.groupby("Pclass")[["Age","Fare"]].sum()
다중 그룹
- 그룹핑에 기준이 두 개 이상
1
2
# 성별과 등급 별 값
df.groupby(["Sex", "Pclass"]).mean(numeric_only=True)
crosstab
- 범주형 데이터에 대한 집계 (비율(%), 대비)
- 범주형 데이터 비교 분석에 유용
- 행에 비치될 데이터(그룹핑), 열에 비치될 데이터(계산 대상)를 따로 지정
1
pd.crosstab(df["Sex"], df["Survived"]) # 행, 열에 비치될 데이터를 따로 지정 (행: "Sex", 열: "Survived")
1
pd.crosstab(df["Pclass"], df["Survived"])
crosstab - 범주별 비율 구하기
normalize : 정규화하다.normalize = 'all': 전체 합이 100%normalize = 'index': 행별 합이 100%normalize = 'columns': 열별 합이 100%- 여자 100명: 많은가 적은가? 구분 불가!!! but, 여자 90% : 많다!
단일 인덱스, 컬럼의 범주표
normalize = ‘all’
- 행, 열의 총합이 1
1
pd.crosstab(df["Sex"], df["Survived"], normalize = 'all', margins = True) # margins = True: All에 행, 열 별 합계 값이 출력
[결과]
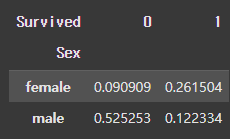
normalize = ‘index’
- index 방식 : 행 방향의 데이터가 기준이 된다.
1 2 3 4 5
# 성별 기준 # ex) female 중 사망한 사람이 0.257962, female 중 생존한 사람이 0.742038 ( 행의 합이 1.0 ) # male 중 사망한 사람이 0.811092, male 중 생존한 사람이 0.188908 (행의 합이 1.0 ) # 전체 중 사망한 사람이 0.616162, 전체 중 생존한 사람이 0.383838 ( 행의 합이 1.0 ) pd.crosstab(df["Sex"], df["Survived"], normalize = 'index', margins = True)
[결과]
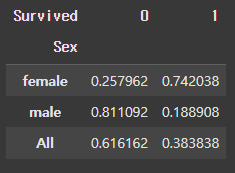
normalize = ‘columns’
- columns 방식 : 열 방향의 데이터가 기준이 된다.
1
2
3
4
5
# Survived 기준
# ex) 사망한 사람 중 female이 0.147541, male이 0.852459( 열의 합이 1.0 )
# 생존한 사람 중 female이 0.681287, male이 0.318713( 열의 합이 1.0 )
# 전체 인원 중 female이 0.352413, male이 0.647587 ( 열의 합이 1.0 )
pd.crosstab(df["Sex"], df["Survived"], normalize = 'columns', margins = True)
[결과]
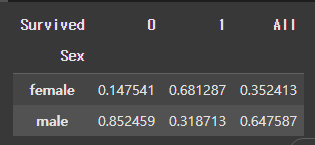
다중 인덱스, 다중 컬럼의 범주표
- index와 columns을 직접 지정
1
2
# "Sex"와 "Pclass"에 대해 "Survived"의 정규화
pd.crosstab(index = [df["Sex"], df["Pclass"]], columns = df["Survived"], normalize = 'all')
[결과]
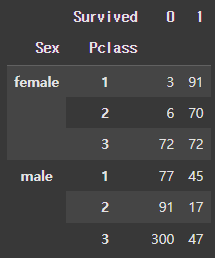
1
pd.crosstab(index = [df['Sex'], df["Pclass"]], columns= [df['Survived'], df["Embarked"]])
[결과]
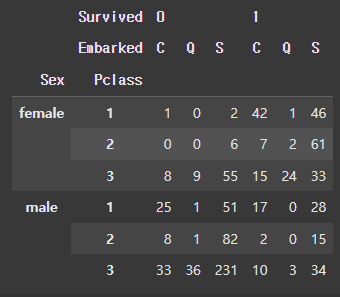
pivot table ⭐️⭐️⭐️
- pivot : 축
- 데이터를 원하는 형태로 집계할 때 아주 유용한 방법.
단일 인덱스, 단일 컬럼, 단일 값
1
2
3
4
5
6
7
8
pd.pivot_table(
df,
index = "Sex", # 행 정의
columns = "Pclass", # 열 정의
values = "Fare", # 값 정의
aggfunc = "mean", # 계산 방법
margins = True
)
[결과]
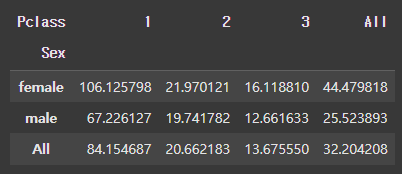
1
2
3
4
5
6
7
8
9
# 집계를 여러 방식으로 한 번에 수행 가능
pd.pivot_table(
df,
index = 'Sex',
columns = 'Pclass',
values = 'Fare',
aggfunc = ['mean', 'min', 'max'],
marigns = True
)
[결과]
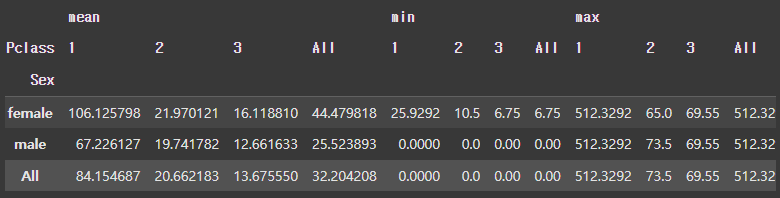
다중 인덱스, 다중 컬럼, 다중 값
1
2
3
4
5
6
7
8
pd.pivot_table(
df,
index = 'Sex', # 성별로 그룹을 잡은 상태
columns = 'Pclass',
values = ["Fare", "Age"],
aggfunc = 'mean',
margins = True
)
[결과]
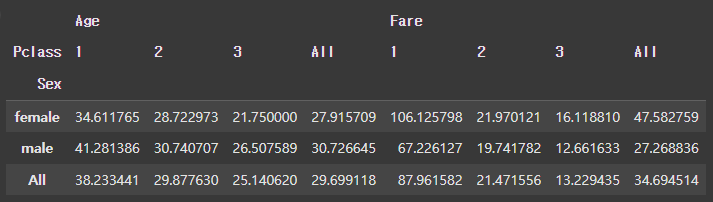
1
2
3
4
5
6
7
pd.pivot_table(
df,
index = ['Sex', 'Pclass'],
columns = ["Survived", "Embarked"],
values = "Fare",
aggfunc = "mean"
)
[결과]
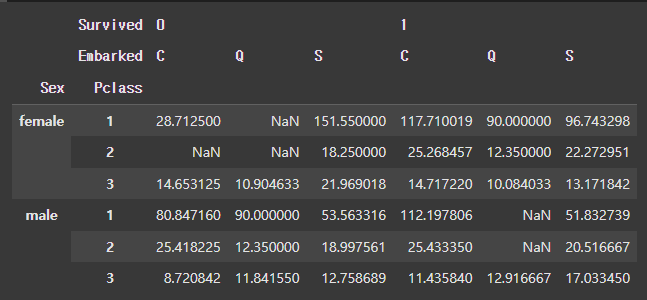
stack, unstack, melt
- 데이터의 재구조화
stack()
- 열(columns) 을 행(row) 의 하위 레벨로 이동
- Long Format
unstack()
- 행(row) 의 하위레벨을 열(columns) 로 이동
- stack의 반대 개념
- Wide Format
melt()
- 컬럼의 정보를 행단위로 가도록 녹여주는
- 컬럼의 정보를 행으로 녹여 해당 정보에 대해 집계가 가능하도록 만든다.
12. 정렬
인덱스 정렬
1
2
df.sort_index() # ascending = True : 오름차순 정렬
df.sort_index(ascending = False) # : 내림차순 정렬
컬럼 기준 정렬
1
2
df.sort_values(by="Fare") # 요금 작은 순으로 정렬
df.sort_values(by="Fare", ascending = False)
문자열 값으로도 정렬 가능
1
df.sort_values(by="Name")
두 개 이상도 가능
1
df.sort_values(by = ["Pclass", "Fare"], ascending = [True, False]) # Pclass는 낮은 순(1,2,3), Fare은 높은 순
loc와 iloc 차이점?
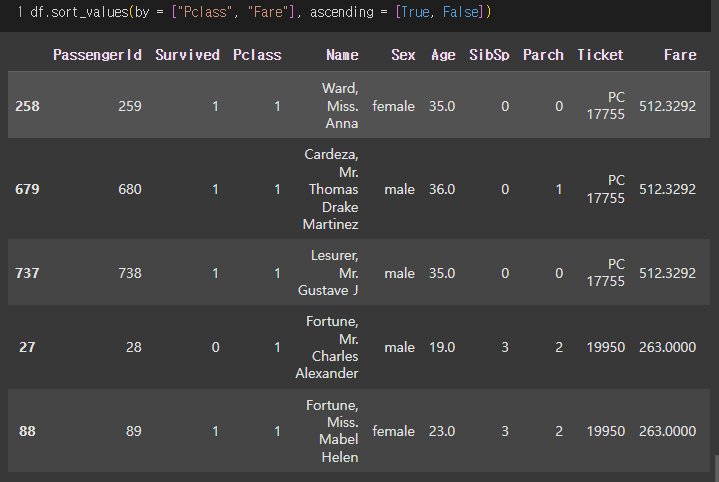
위의 표에서 loc와 iloc로 행을 선택할 때
1
2
3
4
# loc는 offset index 기준이 아니기 때문에, 표 그대로의 범위를 직접 입력
df_sorted.loc[737:88]
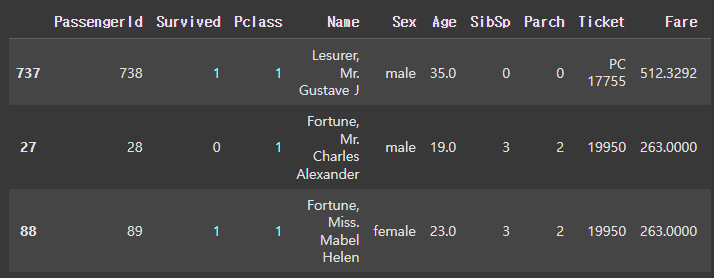
# iloc는 인덱스 기준으로 인덱스로 입력
df_sorted.iloc[2:5]
[결과 같음]
This post is licensed under CC BY 4.0 by the author.