[학습로그] Pandas의 stack, melt
서론
학습로그를 처음 작성하기에 앞서, 내가 수업시간에 헷갈리던 부분이 무엇인가 작성한 코랩 파일을 하나씩 보며 되짚어봤다. 여러가지가 있었지만… 그 중에서도 잘 이해가 되지 않았던 stack과 melt가 눈에 들어왔다. 중요한 집계 파트이기도 했고, melt가 중요하다고 말씀하신 거 같았기에, 이번 기회에 확실히 개념을 잡고 넘어가면 좋을 거 같았다. stack과 melt의 용도를 헷갈리기 전에, 집계란 무엇인지 정확히 알고 가자.
본론
집계란?
여러 개의 값을 모아(‘집’) 계산하여(‘계’) 하나의 값으로 요약하는 과정이다. 대표적인 집계 함수로는 mean(), min(), max() 등이 있다.
이때, 집계의 기준이 되는 데이터(집합)는 반드시 행(row) 단위여야 한다. 예를 들어, 데이터프레임의 컬럼이 ['이름', '국어', '수학', '영어']로 구성되어 있을 때, '이름'이라는 컬럼 아래 존재하는 행 단위의 각 학생의 평균 점수를 계산하는 것은 가능하지만, '과목'이라는 컬럼명이 존재하지 않는 상태에서는 '국어', '수학', '영어' 별로 집계를 수행할 수 없다.
이제 집계에 대해 이해했다. 이러한 집계를 수행해주는 pandas의 함수들 중, stack과 melt의 차이점을 명확하게 이해해보자.
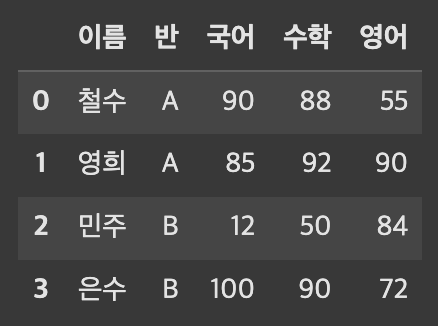
집계에 사용할 간단한 DataFrame을 생성한다.
1
2
3
4
5
6
7
8
9
10
import pandas as pd
df = pd.DataFrame({
"이름": ["철수", "영희", "민주", "은수"],
"반" : ["A", "A", "B", "B"],
"국어": [90, 85, 12, 100],
"수학": [88, 92, 50, 90],
"영어": [55, 90, 84, 72]
})
df
[출력]
df의 index와 columns을 확인해보자
1
2
# index 정보 확인
df.index
[출력]
RangeIndex(start=0, stop=4, step=1)`
1
2
# columns 정보 확인
df.columns
[출력]
Index([‘이름’, ‘반’, ‘국어’, ‘수학’, ‘영어’], dtype=’object’)
해당 df를 사용하여 stack, melt에 대해 자세히 이해해보자. stack과 melt를 이해하기에 앞서, 보통의 DataFrame 컬럼은 멀티인덱스를 갖지 않는다. 따라서 pivot_table을 통해 집계를 시행하여 컬럼에 멀티인덱스를 만든 뒤에, stack과 melt를 적용해보자.
pivot_table
- 컬럼에 있는 것들을 직접 index, columns, values,으로 지정하고, 원하는 집계 방법을 aggfunc에 적는다.
- 매개변수에는 컬럼만을 지정할 수 있다.
pivot_table 생성 형식
1
2
3
4
5
6
7
df_pivot = pd.pivot_table(
df,
index = "A", # 행 인덱스로 사용할 컬럼
columns = "B", # 열(컬럼)으로 사용할 컬럼
values = "C", # 값으로 사용할 컬럼
aggfunc = "mean" # 값을 집계할 함수
)
pivot_table을 이용해 반 별 전체 과목 평균, 최소, 최대 값을 구해보자.
1
2
3
4
5
6
7
8
# 반 별 과목 평균, 최소, 최대
df_pivot = pd.pivot_table(
df,
index = '반',
values = ['국어','수학', '영어'],
aggfunc = ['mean', 'min', 'max']
)
df_pivot
[출력]
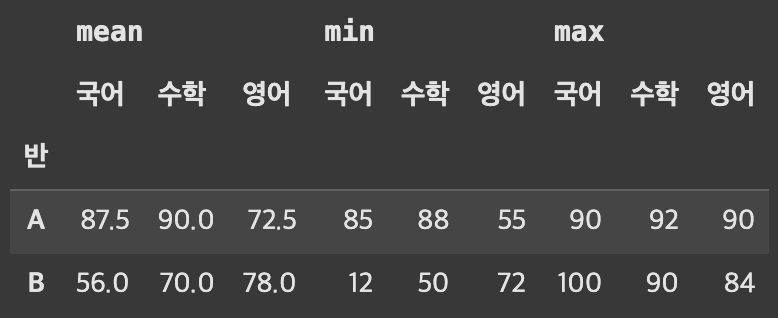
- columns에
MultiIndex가 생성되었다. - columns의
MultiIndex level은 다음과 같다 - 표와 가까울수록
하위 레벨, 멀 수록상위 레벨이다.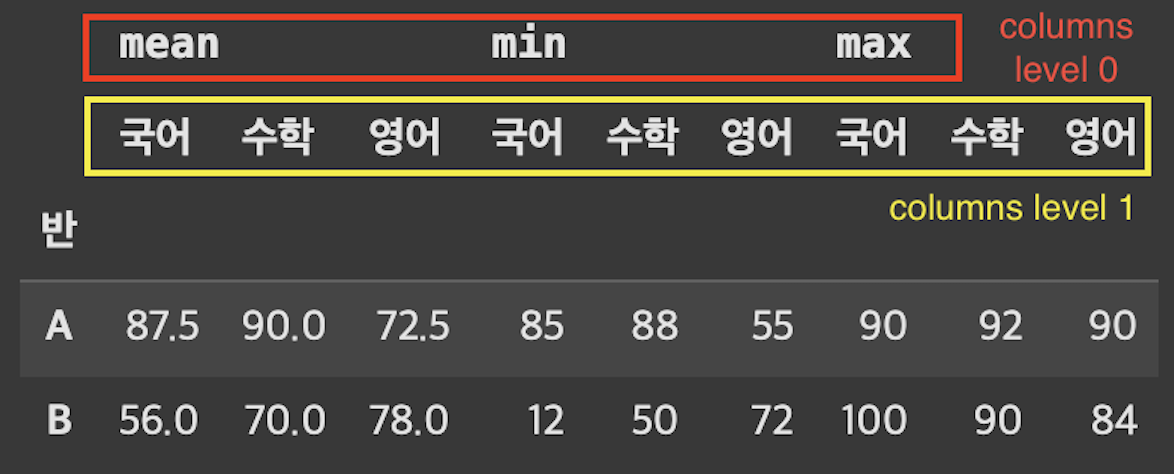
df_pivot의 index와 columns를 확인해보자
1
df_pivot.index
[출력]
Index([‘A’, ‘B’], dtype=’object’, name=’반’)
1
df_pivot.columns
[출력]
1
2
3
4
5
6
7
8
9
10
MultiIndex([('mean', '국어'),
('mean', '수학'),
('mean', '영어'),
( 'min', '국어'),
( 'min', '수학'),
( 'min', '영어'),
( 'max', '국어'),
( 'max', '수학'),
( 'max', '영어')],
)
이렇게 표의 출력과 index와 columns를 확인을 통해 컬럼이 멀티인덱스로 변경됨을 확인할 수 있다. 이 상태에서 stack을 사용한다면 어떤 변화가 일어날까?
스택의 특징은 다음과 같다.
stack
컬럼 레벨단위로 지정해서행 인덱스로 내린다.- 행 인덱스는
MultiIndex가 됨 - 표가 가로로 너무 길 경우(wide format), 세로로 길게 만들 수 있음(long format)
- 행 인덱스는
- 집계를 하기 위한 기능은 아니다!
멀티인덱스는 집계가 불가능하기 때문.
- stack() 안에 컬럼 레벨을 지정하지 않으면 가장 하위레벨이 자동으로 선택 된다.
- 결과적으로, 기존 표의 구조를 바꿔서 보기 쉽게 만든다.
stack() 사용 형식
1
2
# 지정된 컬럼 레벨이 행 인덱스로 stack됨.
df.stack(컬럼레벨)
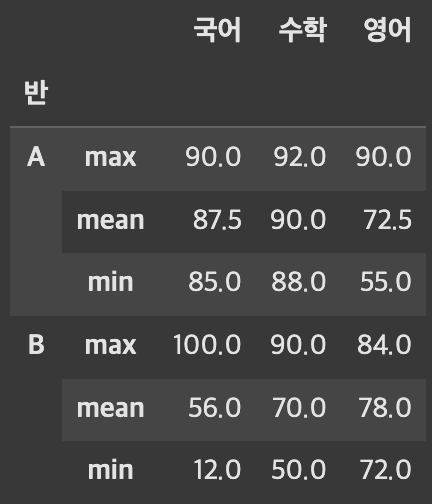
df_pivot에 stack 적용 후 결과 확인
상위 레벨선택 (level 0)1 2
# mean, min, max 컬럼을 행인덱스로 df_pivot.stack(0)
[출력]
하위 레벨선택 (level 1)1 2
# 국어, 수학, 영어 컬럼을 행인덱스로 df_pivot.stack()
[출력]
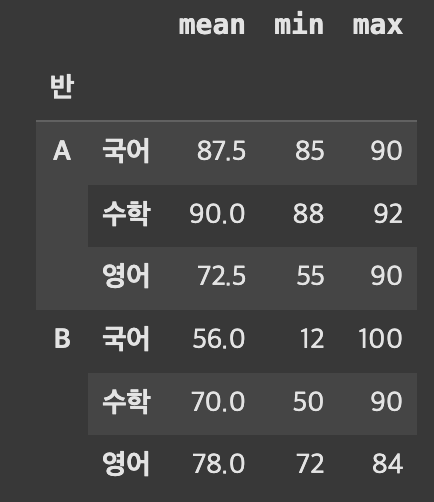
df_stack 생성
- df_stack에 df_pivot.stack()을 저장한다.
1 2
# 국어, 수학, 영어 컬럼을 행인덱스로 df_stack = df_pivot.stack()
index와 columns를 확인해보자
1
df_stack.index
[출력]1 2 3 4 5 6 7
MultiIndex([('A', '국어'), ('A', '수학'), ('A', '영어'), ('B', '국어'), ('B', '수학'), ('B', '영어')], names=['반', None]) - stack에 의해 내려온
'국어', '수학', '영어'컬럼들이 기존 행 인덱스인'반'과 결합되어멀티인덱스가 되었다.1
df_stack.columns
[출력]
Index([‘mean’, ‘min’, ‘max’], dtype=’object’)
또한 stack의 반대 개념인 unstack이 존재하는데, stack의 반대 개념이므로 가볍게 보고 넘어가자.
unstack()
- 행의
멀티인덱스를 컬럼으로 올린다.- stack()의 반대개념이다.
- stack()을 실행한 DataFrame을 unstack하면 처음 형태가 된다.
1
2
stack : 컬럼 -> 행
unstack : 행 -> 컬럼
unstack() 사용법
1
df.unstack(행 인덱스 레벨)
unstack으로 stack 결과 원상복구
1
df_stack.unstack()
[출력]
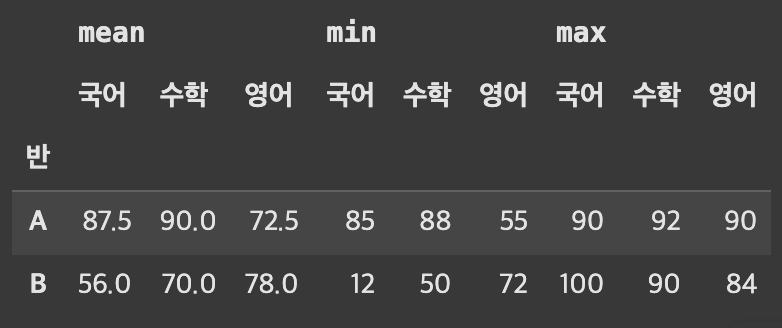
- 행 인덱스의 가장 하위레벨이었던
'국어', '수학', '영어'가 컬럼인덱스의 가장하위레벨이 되었다.
위의 과정을 통해, stack은 컬럼레벨을 행의 인덱스로 만드는 것을 알게 되었다. 또한 stack을 통해 컬럼을 행 인덱스로 내리면, 인덱스가 합쳐져 멀티인덱스가 됨을 알았다.
컬럼이 멀티인덱스인 경우 가로로 표가 길어져 가독성이 떨어지기 때문에 stack을 통해 표의 구조를 보기 좋게 바꿀 수 있다. 멀티인덱스는 집계의 ‘집’, 즉 그룹을 모으는 과정에 사용할 수 없다. 그저 데이터를 구분하는 역할에 그친다. 따라서 stack의 사용 목적은 집계가 아닌, 표의 형태를 보기 좋게 바꾸는 데에 주로 사용된다.
이제 melt를 이해하고, stack과 melt의 차이점을 이해해보자.
melt
- 기준을 잡은 컬럼들을 제외하고, 남은 컬럼들을 하나의 컬럼으로 녹임.
- 따라서 카테고리가 컬럼에 있다면, 해당 카테고리에 대해 집계를 할 수 있게 해준다.
특징을 살펴보면 stack과의 차이를 볼 수 있다. stack은 컬럼을 행인덱스로 만드는 것이고, melt는 컬럼들을 기준을 두고 하나의 컬럼으로 녹이는 것이다. 뭔가 알쏭달쏭 알 것 같지만, 아직 헷갈리기 때문에 직접 사용해서 비교해보자.
melt() 사용 형식
1
2
3
4
pd.melt(
df,
id_vars=[고정할 컬럼], value_vars=[녹일 컬럼], var_name="새 컬럼 이름", value_name="새 값 컬럼 이름")
melt()를 사용하여 국어, 수학, 영어를 과목이라는 하나의 컬럼으로 녹이기
1
2
3
4
5
6
df_melt = df.melt(
id_vars=['이름', '반'], # '이름'과 '반'을 기준으로 잡는다.
var_name = '과목', # 새롭게 녹여진 컬럼의 이름을 지정해준다.
value_name = '점수'
)
df_melt
[출력]
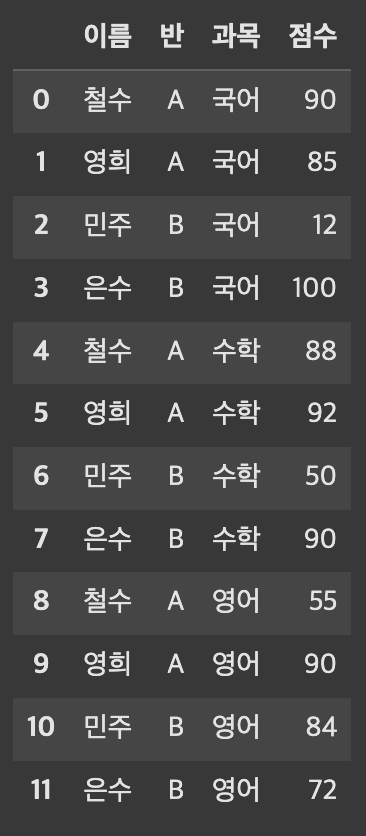
df_melt의 index와 columns을 확인하자
1
df_melt.index
[출력]
RangeIndex(start=0, stop=12, step=1)
1
df_melt.columns
[출력]
Index([‘이름’, ‘반’, ‘과목’, ‘점수’], dtype=’object’)
멀티인덱스가 생성되지 않았다.'국어', '수학', '영어'가'과목'이라는 카테고리로 묶여 컬럼 하나로 녹았다.'국어', '수학', '영어'의 값은'점수'컬럼에 녹았다.
melt를 사용하기 전의 df는 과목(국어, 수학, 영어)이 컬럼에 각각 존재했기 때문에 ‘과목’별로 집계가 불가능 했는데, melt를 사용하여 과목들을 하나의 컬럼으로 녹여냈으므로, 과목 별 집계가 가능하다!
- 그렇다면 group by를 통해 과목 별로 집계를 수행해보자.
과목별 점수 평균 집계
1 2
df_t = df_melt.groupby("과목").mean(numeric_only=True) df_t
[출력]

결과적으로 melt는 카테고리 컬럼들을 하나로 합쳐서 해당 카테고리에 대해 집계가 가능하도록 표를 바꿔주는 함수이다. 그리고 stack은 컬럼 레벨을 행인덱스로 바꿔서 wide format인 표를 long format으로 전환시켜 보기 좋게 해주는 함수이다. 이때, 행 인덱스가 멀티인덱스가 되기 때문에, 컬럼 카테고리로 집계를 하기 위해서는 melt를 사용하는 게 적절하다.
| 구분 | stack | melt |
|---|---|---|
| 정의 | 컬럼을 행 인덱스로 내리는 변환 | 컬럼을 녹여서 하나의 컬럼으로 만드는 변환 |
| 작동 방식 | 컬럼 레벨을 하나의 인덱스로 변환 (멀티인덱스 생성) | 지정한 컬럼을 기준으로 나머지 컬럼들을 두 개의 컬럼 (variable, value)으로 변환 |
| 주요 특징 | 컬럼이 행 인덱스로 이동하며 데이터 형태가 길어짐 | 여러 컬럼을 하나의 컬럼으로 합쳐서 긴 형태로 변환 |
| 인덱스 변화 | 멀티인덱스 생성 가능 | 기존 인덱스 유지 |
| 사용 예시 | df.stack() | pd.melt(df, id_vars=["기준 컬럼"]) |
| 주로 사용하는 상황 | 멀티인덱스가 필요할 때 | 데이터 시각화를 위해 긴 형태(long format)로 변환할 때 |
마무리
학습로그를 태어나서 처음 작성해 보았는데, 내가 모르는 부분을 시간내서 조사하고, 이해하는 게 생각보다 재밌어서 좋았다. 그러나 조사하고 공부한 내용들을 머릿속에서 꺼내서 예쁘게 작성하는 게 어려웠다. 아직 요령이 없어서 그렇다고 생각한다. 앞으로 꾸준히 작성해서 멋진 블로그를 만들 수 있도록 노력해야겠다.
링크
- 참고 링크
- https://velog.io/@xindex/python-StackUnstack-Pivot-Melt
- https://velog.io/@midoi327/Pandas-%EB%8D%B0%EC%9D%B4%ED%84%B0-%EB%B3%80%ED%99%98-T-pivot-melt-stack-unstack-crosstab-sort-duplicated
- https://www.inflearn.com/community/questions/453877/stack%EA%B3%BC-melt%EC%9D%98-%EC%B0%A8%EC%9D%B4?focusComment=170541